Unleashing the Power of RAG for Smarter AI Design Assistants
Let's explore a foundational feature of the AI design assistants we integrate into our conversational configurators: Retrieval-Augmented Generation (RAG).


At Salsita, our mission is to develop industry-leading Conversational UI interfaces by leveraging the latest advancements in generative AI technology. To deliver tangible value to end users, we prioritize creating interfaces that are both reliable and easy to use.
Today, let's explore a foundational feature of the AI design assistants we integrate into our conversational configurators: Retrieval-Augmented Generation (RAG).
The Challenge
Harnessing a Large Language Model (LLM) to create an effective AI design assistant requires careful prompt engineering. Among the many functionalities we expect, it must be able to accurately respond to any relevant questions a user might ask.
Users often inquire about the product itself—questions like "How powerful is the oven?" or "What colors are available?" They might also seek information about the company or sales-related queries such as "How do I contact support?" or "Do you deliver to Germany?" and "What are the warranty options?"
Furthermore, it would be ideal if the AI design assistant could guide users on how to perform tasks using the traditional UI, for those who prefer a hands-on approach. Queries might include, "How do I change the style?" or "How do I set the width?"
While LLMs are trained on vast amounts of general knowledge data, the specific information we need for our AI design assistant pertains to particular products and the configurator. Relying on general knowledge is risky, as LLMs may generate incorrect or fabricated responses—potentially leading to inaccuracies or outright falsehoods.
Enter RAG: Retrieval-Augmented Generation
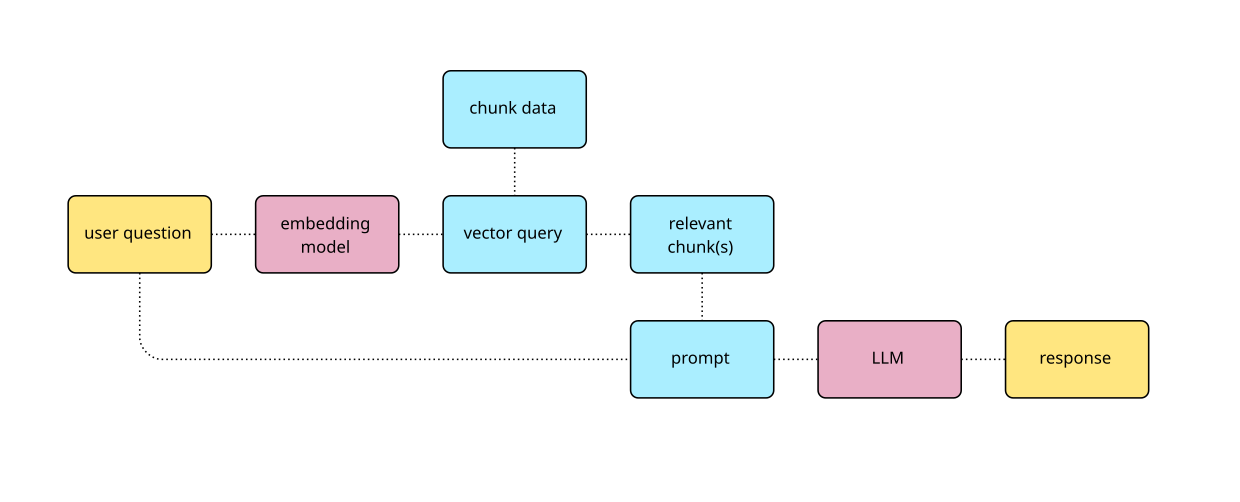
To address this challenge, we implement Retrieval-Augmented Generation (RAG). This approach involves retrieving the most relevant textual information based on the user's input and incorporating it into the conversation. This ensures that the AI design assistant’s responses are as accurate as possible.
To evaluate the relevance of specific text, we use vector embedding. This process uses a vector embedding model, to assign an N-dimensional vector (essentially coordinates in an N-dimensional space) to a given string of text. Two pieces of text with related content will be assigned similar vectors, while unrelated content will have very different vectors. By measuring the distance between these vectors, we can determine the relevancy of the text.
Let's assume we have a collection of documents containing all the information we want the user to access in the conversational configurator. How do we process them to ensure relevant information can be easily retrieved in response to a user's query?
The Art of Chunking
The first step is to divide documents into manageable chunks of text. There are several methods to do this, but the general goal is to break the information down into pieces that are neither too small nor too large. Each chunk should contain enough context to be relevant only when needed.
Using smaller chunks increases the number of pieces, which can demand more processing power during querying. Conversely, larger chunks will increase the prompt size and may dilute the focus on the required information, raising the risk of hallucinations from the LLM.
A straightforward approach is to split the document into chunks containing a set number of words with some overlap to ensure content is evenly distributed. However, this method has drawbacks — chunks may split mid-sentence, leading to loss of coherence and introducing noise, as fragmented sentences might lose their original meaning. Additionally, a single chunk could contain unrelated information.
More sophisticated chunking strategies, such as recursive text splitting, text tiling, or content-specific splitting, can be employed. While this article won't delve into these methods, they are well-documented and readily available in online resources.
Regardless of the chosen method, the outcome will be an array of text chunks, each paired with its corresponding vector embedding.
Efficient Chunk Storage and Querying
With our data now organized into chunks, the next consideration is how best to store and query it.
While storing and querying data in memory is possible, it doesn’t scale well as data size grows on the server.
A more practical solution is to use a vector database. Numerous dedicated vector database systems are available, such as Chroma, Marqo, Weaviate, and Pinecone. Alternatively, a general-purpose database with vector support, like PostgreSQL, OpenSearch, or Elasticsearch, can be used. This approach is advantageous when the application already utilizes such a database for conventional data storage, keeping the tech stack more streamlined.
Regardless of the storage method, the querying process follows these general steps:
- Calculate the vector embedding of the user's input message.
- Query the database to retrieve one or more text chunks with the most similar vector values.
The retrieved chunks are then integrated into the request to the LLM, providing it with a clear and precise context to answer the user's query effectively.
Conclusion
By leveraging the latest AI techniques, we can significantly improve the experience for end users, driving greater engagement and boosting conversion rates on our conversational configurators.
With today’s technology, we have the power to create the user experiences of tomorrow!
Try out a Conversational Configurator
We developed this Conversational Configurator for L’Atelier Paris. It allows users to design high-end kitchens in real-time with the help of an AI design assistant.
Sophie, the AI design assistant for L’Atelier Paris, helps users design their kitchen range by asking discovery questions, providing expert advice and information about the product, configurator, and company, and applying changes in real-time. The AI design assistant understands natural language, so users don't have to use specific phrasing.
Try it out:

